CDCS PhD Affiliates Present at DH2023 Conference
The Alliance of Digital Humanities Organizations (ADHO) hosted its conference in Austria this year, and CDCS was delighted to see that our community was strongly represented with papers from several University of Edinburgh researchers.

Lucy Havens is based in the School of Informatics, where she is researching bias in cultural heritage metadata. Combining natural language processing and data visualisation technologies, she seeks to identify and classify bias present in the language of cultural heritage catalogues. She conducts this research through case studies with cultural heritage collections, such as the Archives at the University of Edinburgh. She presented her paper “Collaboration Across the Archival and Computational Sciences to Address Legacies of Gender Bias in Descriptive Metadata” (Lucy Havens, Beatrice Alex, Rachel Hosker, Benjamin Bach, Melissa Terras). This presentation reports on a case study investigating how Natural Language Processing technologies can support the measurement and evaluation of gender biased language in archival catalogues. Working with English descriptions from the catalogue metadata of the University of Edinburgh’s Archives, the project created an annotated dataset and classification models that identify types of gender biases in the descriptions. Though conducted with archival data, the case study holds relevance across Galleries, Libraries, Archives, and Museums (GLAM), particularly for institutions with catalogue descriptions written in English. In addition to bringing Natural Language Processing methods to Archives, they identified opportunities to bring Archival Science methods, such as Cultural Humility (Tai, 2021) and Feminist Standpoint Appraisal (Caswell, 2022), to Natural Language Processing. Through this two-way disciplinary exchange, they demonstrate how Humanistic approaches to bias and uncertainty can upend legacies of gender-based oppression that most computational approaches to date uphold when working with data at scale.
Of her experience at the conference Lucy said, “This was my first time attending a Digital Humanities (DH) Conference so I really enjoyed seeing the variety of work people were presenting. To give a sense of the variety, I saw presentations about colour pigments in Indian and South Asian art, the locations of DH conferences and subsequent travel implications for attendees, natural language processing technology applied to poetry (from the University of Edinburgh's Anouk Lang), and close listening (as in not with machine learning) of recordings of stories and songs from audio archives of Zora Neale Hurston. It was great to catch up on the latest work of fellow PhD students at the University of Edinburgh who also presented at the Conference!”

Yi Li is based in the School of Literatures, Languages and Cultures. Yi's research focuses on representing Diversity and Inclusion in children’s literature in China and the UK, through interdisciplinary methods such as Text Mining, Sentiment Analysis, coded Content Analysis. Data in her PhD research would be collected from the online databases and analysed with computational methods. Yi presented her paper “Implicit Gender Inequality in Children’s Picture Books: Evidence from a Text Mining Analysis of 200 Bestselling Chinese and British Titles” (Yi Li, Melissa Terras, Yongning Li). In this paper Yi describes how term frequency and sentimental analysis were used on 200 Chinese and British bestselling picture books from 2011–2020. It was found that gender inequality still exists in both mainstream picture book markets – from the textual perspective. However, the UK titles feature more female presentations and feminine narratives in the texts than the Chinese titles. Yi described her time at the conference to us, “Attending DH2023 in Graz was a fantastic experience; I met many folks working in DH with diverse projects. Different from last year, this conference enabled me to discuss related research with other people in this area in real life.”

Joe Nockels is based in the School of Literatures, Languages and Cultures. Joe's project explores how Handwritten Text Recognition (HTR) is changing access to digitised material; both from a user and institutional perspective. With artificial intelligence becoming readily used in the recognition of handwriting, producing automated transcriptions, this project will work closely with those behind the leading software Transkribus; exploring how it may benefit the users of the National Library of Scotland whilst moulding users’ general philosophy towards digital material. Joe presented on the need to establish best practice surrounding handwritten text recognition (HTR) use. HTR’s efficacy for automatically converting handwritten scripts into machine-readable format, presenting transcriptions in a variety of ways (Muehlberger et al., 2019), is now proven. This raises the question of what impact this will have on the study of history in the near future, defined as the next ten years. In response, they provided a speculative design for HTR and the six primary issues raised by wider HTR use. HTR is beginning to shift historical methods and practice, from sampling data to, as Muehlberger et al. (2019) describe an exhaustive interrogation of primary sources. Therefore, a horizon scan of the impact of this technology is essential, pre-empting and addressing social, ethical, and technical issues. This presentation also touched on how HTR's application will generate new knowledge of and from the past. Joe described to us his experience at the conference, “Attending the first in-person meeting of DH for four years was something special, fostering new collaborations, conversations and joint thinking. Meeting with people you have only seen through a screen before was surreal at first, but the local organisers helped create a vibrant and warm conference. I hope to attend the next DH24 at George Mason University. You can find more information at @DHinDC2024.”
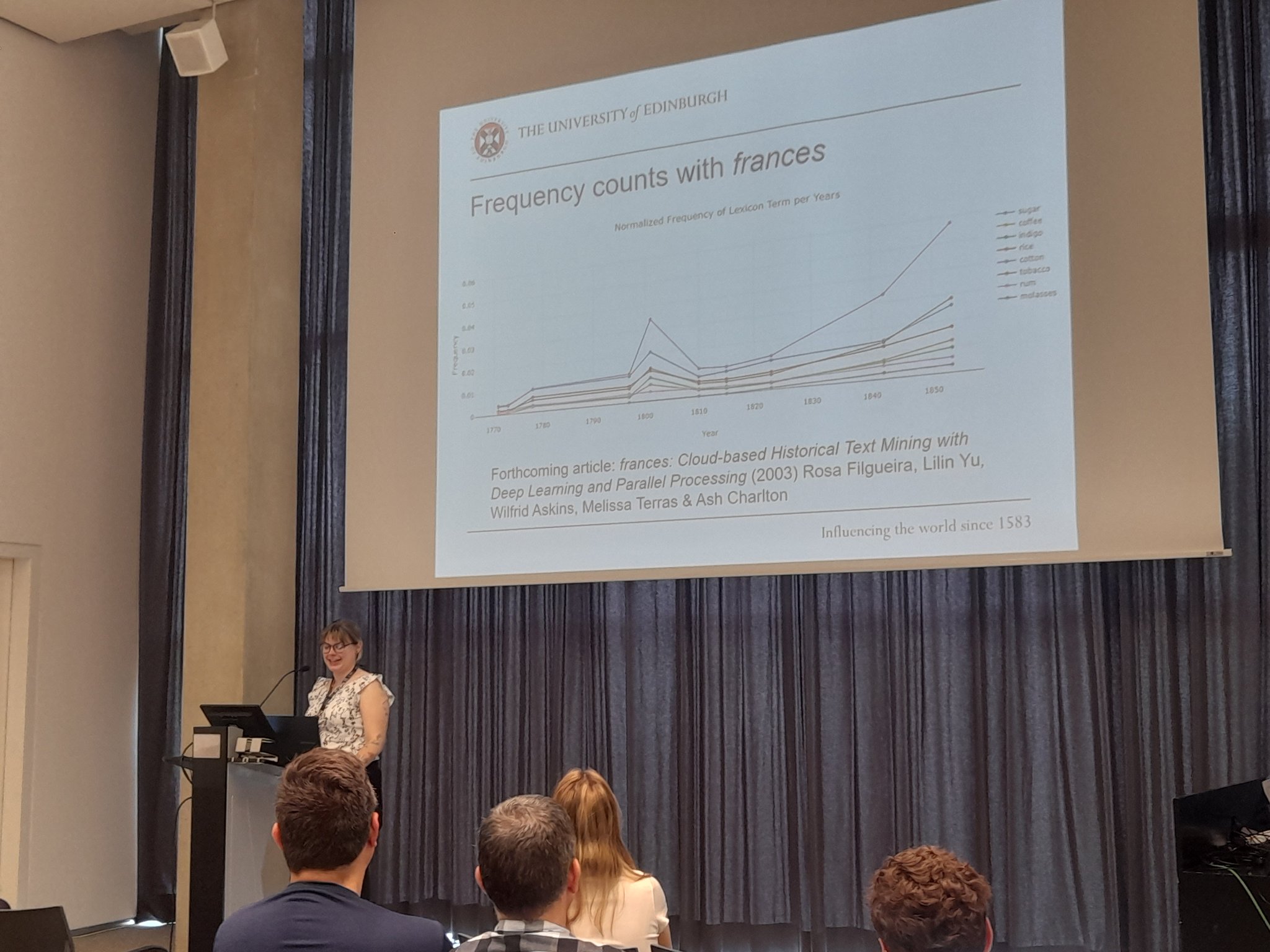
Ash Charlton is a second-year PhD student who is working on a Collaborative Doctoral Award PhD with the University of Edinburgh and National Library of Scotland, funded by the Scottish Graduate School for Arts and Humanities. She is based in the History department, in History, Classics & Archaeology. The paper she presented was a work-in-progress short presentation on her research into legacies of race and slavery in the early Encyclopaedia Britannica (1768-1860), using a text mining approach. Her paper covered her creation of a machine-readable dataset with handwritten text recognition platform Transkribus, using digitised images from the National Library of Scotland's Data Foundry. She explained her approach and methods for the research, which include identifying frequency counts and the contexts of keywords relating to race and slavery in order to identify broader patterns across the editions, but also to guide close readings of certain articles throughout the editions. Her research will also cover network mapping of connections between the articles, where explicit references are made by the authors of articles or editors, but also to gain an insight into where connections are not made and what conclusions can be drawn from this. Her takeaways from the conference were as follows, “The conference has been an excellent opportunity to meet fellow digital humanists, take part in workshops to improve skills and learn new DH tools, and to engage with presentations on a wide range of areas, from DH pedagogy, community collaboration, NLP approaches, data visualisation, DH ethics and legalities, and everything in-between. Digital humanities is such a wide-ranging and welcoming community and it has been an absolute privilege to be able to spend a week with researchers from across the world.”